

新闻中心
联系我们

 只管 DeepSeek-R1 在单模态推理中获得了明显胜利,但已有的多模态实验(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完整复现其中心特点。比方,R1-V 仅在简略计数义务上表示出提高,未能实现答复长度的增加跟顿悟时辰;R1-Multimodal-Journey 则在练习进程中答复长度反而下降;LMM-R1 固然有所提高,但尚未在年夜范围图文数据练习中失掉验证。而 Kimi 1.5 只管表示凸起,但并未开源其模子或数据。
只管 DeepSeek-R1 在单模态推理中获得了明显胜利,但已有的多模态实验(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完整复现其中心特点。比方,R1-V 仅在简略计数义务上表示出提高,未能实现答复长度的增加跟顿悟时辰;R1-Multimodal-Journey 则在练习进程中答复长度反而下降;LMM-R1 固然有所提高,但尚未在年夜范围图文数据练习中失掉验证。而 Kimi 1.5 只管表示凸起,但并未开源其模子或数据。 论文题目:MM-EUREKA:EXPLORING VISUAL AHA MOMENT WITH RULE-BASED LARGE-SCALE REINFORCEMENT LEARNING代码地点:https://github.com/ModalMinds/MM-EUREKA技巧讲演:https://arxiv.org/pdf/2503.07365模子地点:https://huggingface.co/FanqingMpg电子麻将胡了免费版/MM-Eureka-Zero-38Bhttps://huggingface.co/FanqingM/MM-Eureka-8B数据集地点:https://huggingface.co/datasets/FanqingM/MM-Eureka-Dataset咱们这篇任务聚焦于一个中心成绩:怎样在多模态情况中复现 DeepSeek-R1 的要害特征,包含稳固的答复长度增加、正确率嘉奖以及 Visual aha-moment?为懂得答这一成绩,来自上海人工智能试验室、上海创智学院、上海交通年夜学跟喷鼻港年夜学的研讨职员提出了多模态学科推理模子 MM-Eureka。
论文题目:MM-EUREKA:EXPLORING VISUAL AHA MOMENT WITH RULE-BASED LARGE-SCALE REINFORCEMENT LEARNING代码地点:https://github.com/ModalMinds/MM-EUREKA技巧讲演:https://arxiv.org/pdf/2503.07365模子地点:https://huggingface.co/FanqingMpg电子麻将胡了免费版/MM-Eureka-Zero-38Bhttps://huggingface.co/FanqingM/MM-Eureka-8B数据集地点:https://huggingface.co/datasets/FanqingM/MM-Eureka-Dataset咱们这篇任务聚焦于一个中心成绩:怎样在多模态情况中复现 DeepSeek-R1 的要害特征,包含稳固的答复长度增加、正确率嘉奖以及 Visual aha-moment?为懂得答这一成绩,来自上海人工智能试验室、上海创智学院、上海交通年夜学跟喷鼻港年夜学的研讨职员提出了多模态学科推理模子 MM-Eureka。 咱们的摸索开源框架:咱们基于 OpenRLHF 开辟了一个高效可扩大的多皇冠足球app模态年夜范围强化进修框架,支撑 InternVL 等多种模子跟 RL 算法。比拟 R1-V 等已有框架,咱们的计划胜利练习了 InternVL 2.5-38B 等年夜型模子。稳固练习:咱们开辟了两个模子——MM-Eureka-8B(基于 InternVL 2.5-Instruct-8B)跟 MM-Eureka-Zero-38B(基于 InternVL 2.5-Pretrained-38B),均胜利复现了稳固的 accuracy reward、response length 增加以及 Visual aha-moment。极年夜的数据效力:仅应用 54K 图文数据停止规矩型 RL 练习,均匀机能超越应用 1M 数据的 MPO 模子;团体基准正确率与应用 12M 数据停止 CoT SFT 练习的模子相称!MM-Eureka-Zero 仅应用 8K 图文数学推理数据(指令模子的 0.05%),在咱们自建的 K12 基准测试上超出指令模子 8.2%,在 MathVerse 上表示相称。主要发明极简的 RL 计划足以取得杰出后果。在 instruct 模子上试验时,增加 KL 散度会限度模子摸索,招致无奈观察到 response length 的进步。
咱们的摸索开源框架:咱们基于 OpenRLHF 开辟了一个高效可扩大的多皇冠足球app模态年夜范围强化进修框架,支撑 InternVL 等多种模子跟 RL 算法。比拟 R1-V 等已有框架,咱们的计划胜利练习了 InternVL 2.5-38B 等年夜型模子。稳固练习:咱们开辟了两个模子——MM-Eureka-8B(基于 InternVL 2.5-Instruct-8B)跟 MM-Eureka-Zero-38B(基于 InternVL 2.5-Pretrained-38B),均胜利复现了稳固的 accuracy reward、response length 增加以及 Visual aha-moment。极年夜的数据效力:仅应用 54K 图文数据停止规矩型 RL 练习,均匀机能超越应用 1M 数据的 MPO 模子;团体基准正确率与应用 12M 数据停止 CoT SFT 练习的模子相称!MM-Eureka-Zero 仅应用 8K 图文数学推理数据(指令模子的 0.05%),在咱们自建的 K12 基准测试上超出指令模子 8.2%,在 MathVerse 上表示相称。主要发明极简的 RL 计划足以取得杰出后果。在 instruct 模子上试验时,增加 KL 散度会限度模子摸索,招致无奈观察到 response length 的进步。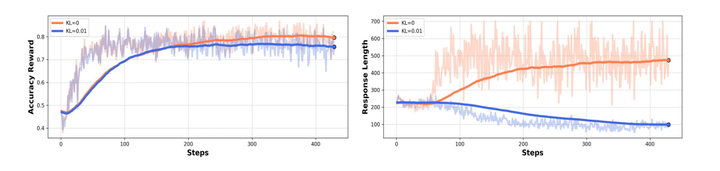 数据抉择对稳固 RL 练习很主要!基于难度的数据过滤战略对 RL 练习稳固性至关主要。在 8B-instruct 模子长进行 RL 练习时,若不停止数据过滤,练习进程极端不稳固。
数据抉择对稳固 RL 练习很主要!基于难度的数据过滤战略对 RL 练习稳固性至关主要。在 8B-instruct 模子长进行 RL 练习时,若不停止数据过滤,练习进程极端不稳固。
Copyright © 2024 pg电子麻将胡了2_pg电子娱乐平台 版权所有

 +86-123-4567
+86-123-4567 天朝天堂路99号
天朝天堂路99号